[ 오늘의 학습 ]
1. 전역 데이터 타입을 데이터 사전에 등록하는 법을 배웠습니다.
이 데이터 유형은 데이터 사전에 등록하면 SAP 전체 시스템에서 전역적으로 사용 가능합니다.
데이터 사전(SE11)에는 여러 개체가 있지만, 모든 개체를 전역 데이터 유형으로 사용할 수 있는 것은 아닙니다.
2. 로컬 데이터 유형으로 구조화 된 객체를 만들고, 인스턴스화 하는 법을 배웠습니다.
3. 전역 데이터 유형으로 구조화 된 객체를 만들고, 인스턴스화 하는 법을 배웠습니다.
4. 내부 테이블에 대해서 배우고, 로컬 데이터 유형으로 구조화 된 객체를 인스턴스화 하여 테이블에 할당하는 법을 배웠습니다.
5. 전역 데이터 유형의 객체를 인스턴스화 하여 테이블에 할당하는 법을 배웠습니다.

SE11에서 전역변수 타입을 만들기 위해 더블클릭합니다.
Serach for Data Elements 클릭합니다.
Information System 클릭합니다.
등록한 전역 데이터 타입을 확인할 수 있습니다.

등록한 글로벌 타입을 실제 코드에서 사용할 수 있게 됐습니다.
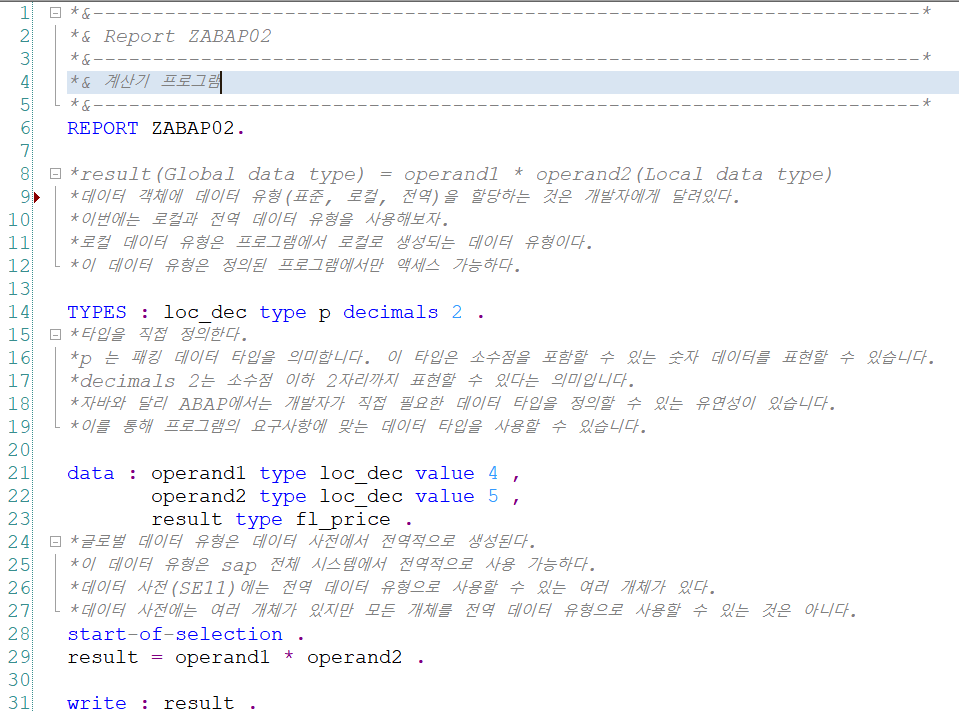
value 키워드를 사용해서 변수를 다이렉트로 할당하는 법을 배웠습니다.

유럽은 소수점 표현 방식이 다릅니다.

[ 구조화된 데이터 타입 정의 ]
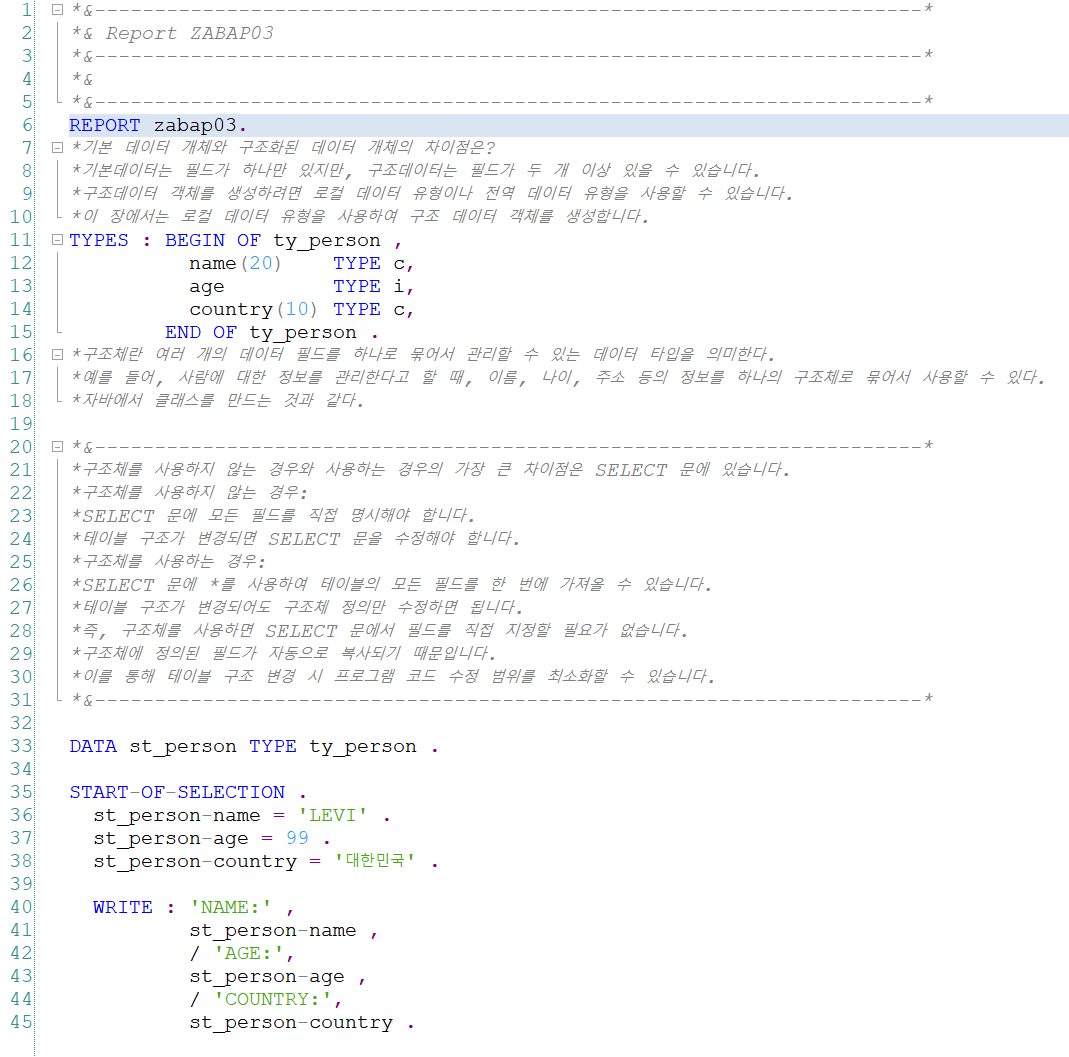
객체화(구조체) 시키는 이유에 대해서 공부하여 주석으로 작성해뒀습니다.
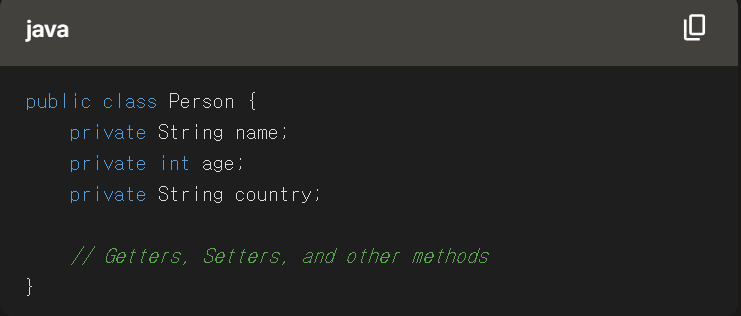
자바에서 클래스 만들고 멤버변수 선언하는 것과 똑같이 생각하면 됩니다.
DATA st_person TYPE ty_person .위에 코드에서 처럼 로컬에서 생성한 객체 타입으로 st_person을 선언하면, 자바에서 객체의 인스턴스 생성하는 것과 같습니다.
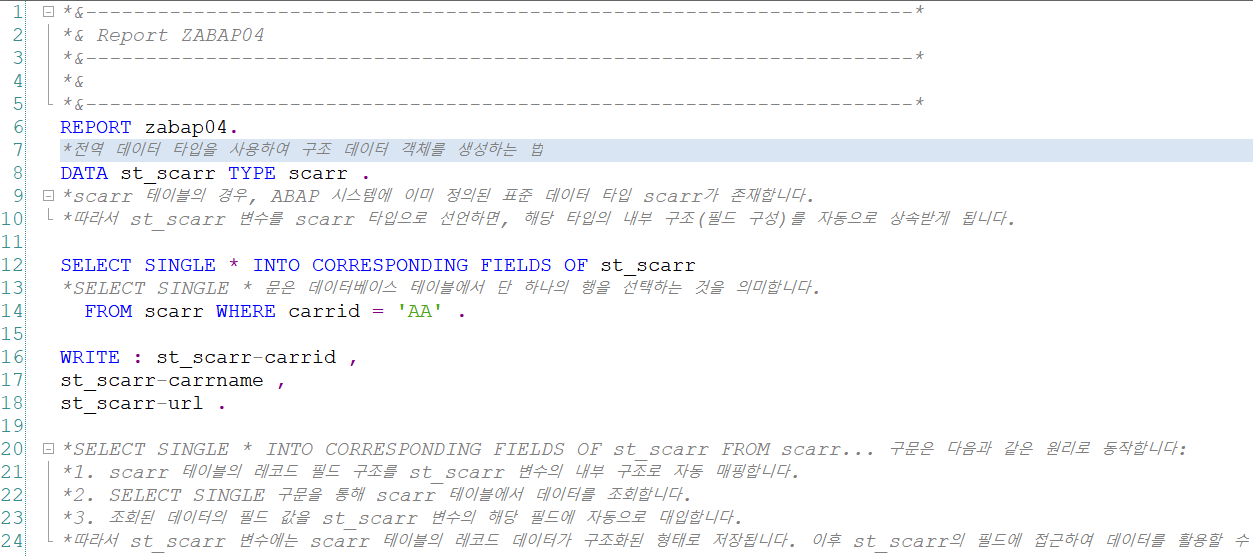
SELECT SINGLE * INTO CORRESPONDING FIELDS OF st_scarr
FROM scarr WHERE carrid = 'AA' .SELECT SINGLE * 문은 데이터베이스 테이블에서 단 하나의 행을 선택하는 것을 의미합니다.
그렇다면 위에 코드는 scarr 테이블에서 carrid가 = 'AA'인 하나의 행을 뽑아서 st_scarr에 할당하는 쿼리입니다.
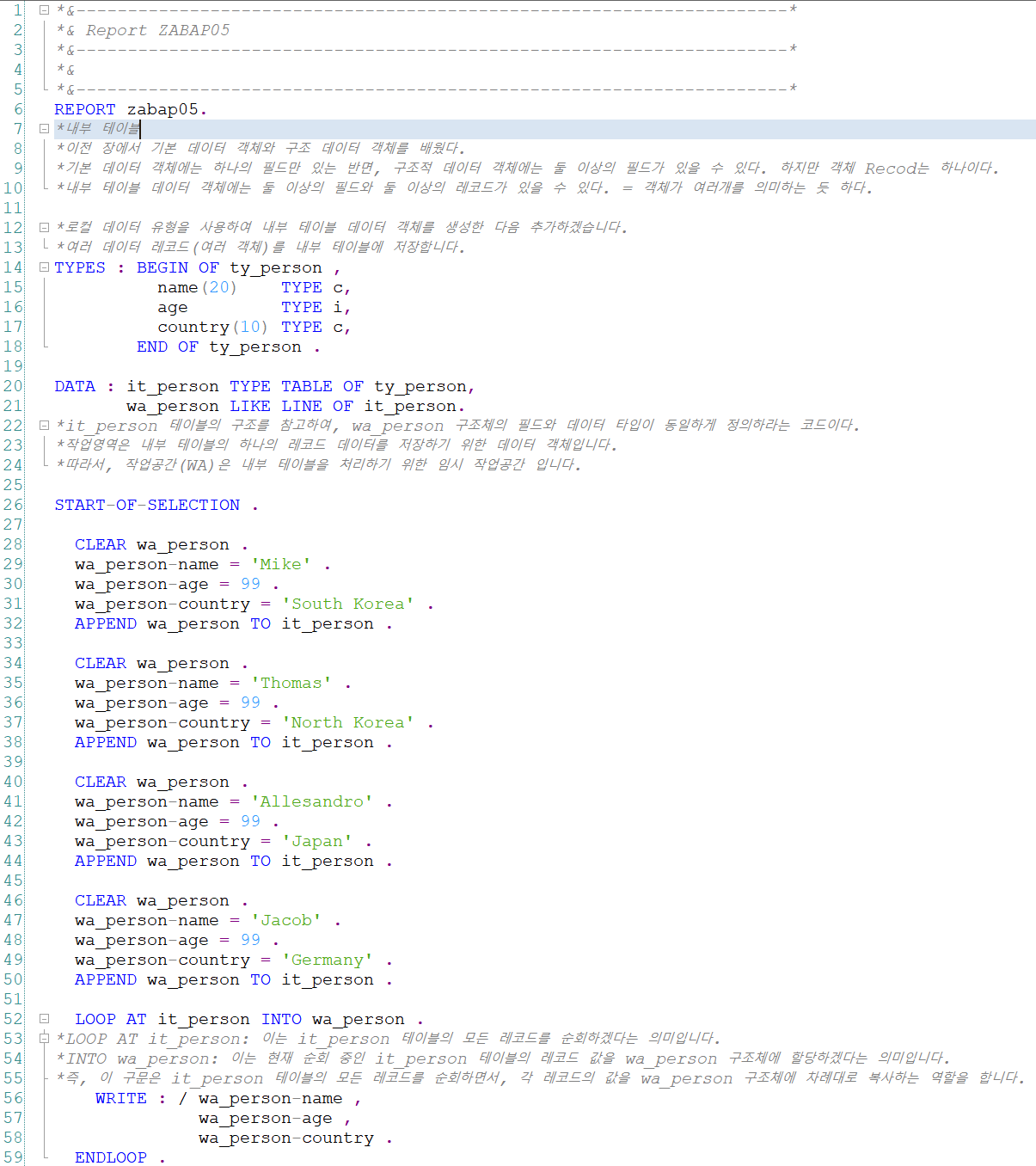
내부 테이블에 같은 타입의 인스턴스화 된 객체를 여러개 담을 수 있습니다.
DATA : it_person TYPE TABLE OF ty_person,
wa_person LIKE LINE OF it_person.it_person 테이블의 구조를 참고하여, wa_person 구조체의 필드와 데이터 타입이 동일하게 정의하라는 코드입니다.
LOOP AT it_person INTO wa_person .it_person 테이블의 모든 레코드를 순회하겠다는 의미입니다.
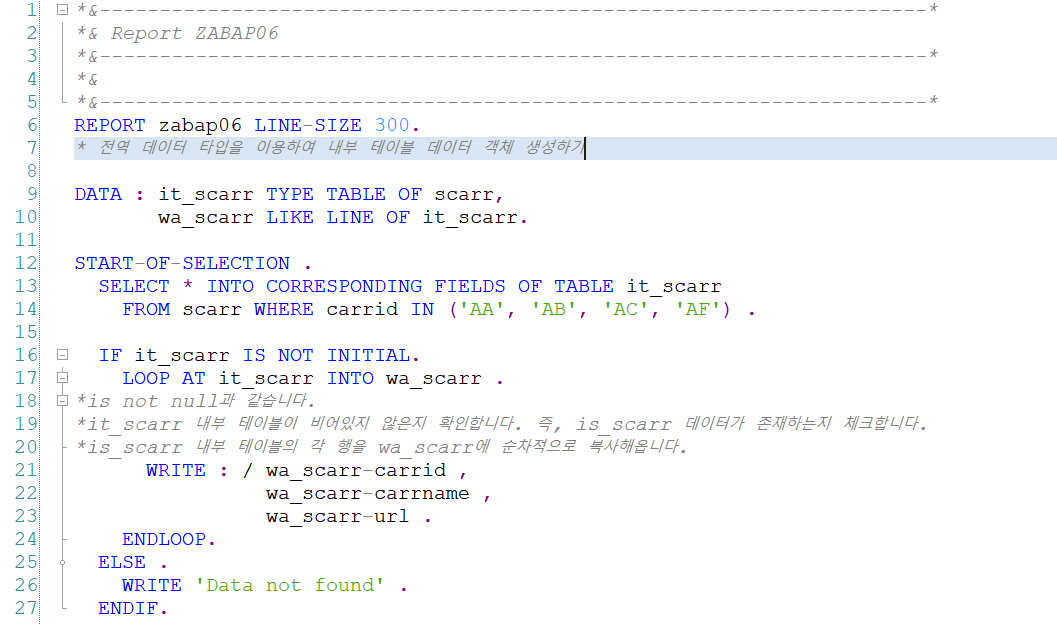
SELECT * INTO CORRESPONDING FIELDS OF TABLE it_scarr
FROM scarr WHERE carrid IN ('AA', 'AB', 'AC', 'AF') .원본 테이블 scarr에서 조건에 해당하는 carrid 필드값이 'AA', 'AB', 'AC', 'AF' 중 하나에 해당하는 모든 행을 선택하고, 선택된 scarr테이블의 모든 필드 값들을 it_scarr라는 내부 테이블의 필드에 복사합니다. 참고로 여러 행을 복붙 하기 때문에 SINGLE이 붙지 않고, 테이블이기 때문에 TABLE 키워드가 들어갑니다.
IF it_scarr IS NOT INITIAL.
LOOP AT it_scarr INTO wa_scarr .MySQL의 is not null과 같습니다. 즉, 데이터가 있다면 반복문으로 wa_scarr에 전부 재할당해주게 됩니다.